Google Knowledge Graph Bias Uncovered
Google’s quest to give users deeper insights when users ask about things (Entities) is flawed from the outset. Understanding how other systems infer topicality provides insight into understanding how knowledge graph bias is inherent in the system due to human influence. This post sets out to expose the flaw. Having understood the flaw, we can also see how Entity search itself is even more game-able than traditional PageRank based machine learning model. “Entity SEO” is born and will inevitably take over from keyword seo.
Google’s Knowledge Graph and what it means for Search Marketing
We mostly see Google’s knowledge graph represented in the SERPs as a block of information about a topic, derived from differing data sources. For example, the one shown below.
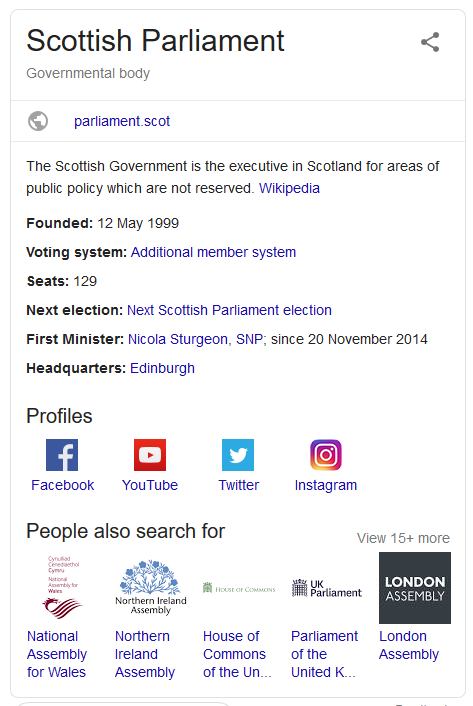
It is a collection of structured and semi structured data which takes Google’s understanding of the Internet from a URL (or more accurately URI) based knowledge system, to an Entity based system.
Types of Bias in Knowledge Graphs.
Scholars at the STKO lab at the University of California wrote a recent vision paper highlighting the need to carry out further research into methods to de-bias knowledge graphs (Citation: Janowicz et al, from the University of California). In the paper they identify several types of bias inherent in the systems:
1: Data Bias
The data itself is biased at the point of generation. We’ll discuss this in much more detail below.
2: Schema Bias
Those ablest to create Schema mark-up do not represent a balanced view of society, opinion or the world of things.
3: Inferential Bias
Given that the underlying data forms the training set for machine learning, there is a very real danger that machines will accentuate the bias, by inferring that all Presidents must be male or other erroneous extrapolations.
This post builds on highlighting the prime cause of the Data Bias described in that paper, as it pertains to Google’s Knowledge Graph.
Cost savings in Entity Search comes at a price.
In the description of “Knowledge Graph” being a migration from an index of URLs to entities sounds small, but ultimately has the potential to save Google billions and helps them scale search beyond what they have already achieved. This is because the knowledge graph needs a very tiny fraction of storage space and processing power to organize data into information and retrieve that information efficiently. It is worth noting at this point how significant the difference is. There are (according to Majestic) 8.5 trillion URLs (Citation: Majestic.com homepage) on the Internet worth noting. By contrast, the number of “things” worth talking about are 2.5 million according to a knowledge graph I have had the pleasure of working with recently. Whilst this is more than twice the size reported by Bing in 2014 and also (I believe) larger than other known graphs it is tiny compared to an index based on URLs.
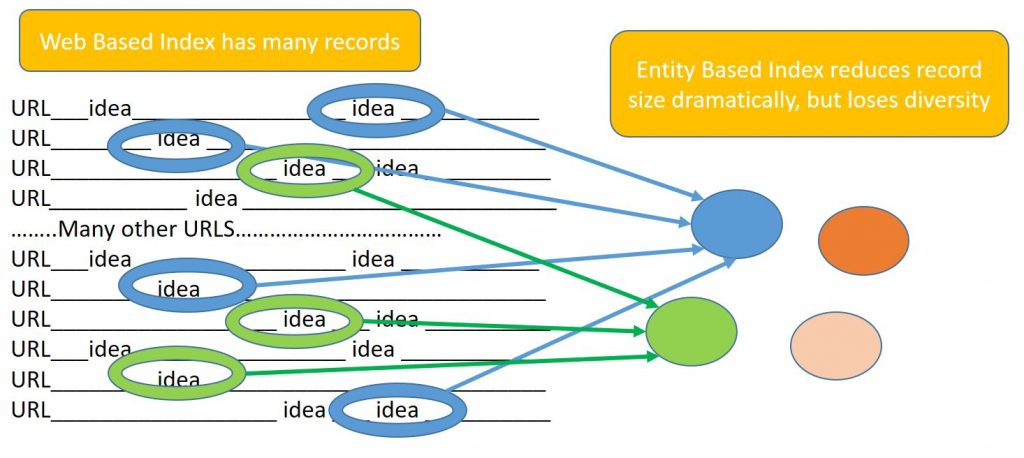
So organizing data by “things” instead of URIs means reducing the length of the records by 2.5M/ 8,500M records… which is 1/3400th the length. That’s one hell of a reduction in overhead! Most content (the argument goes) talks about the same things again and again… so:
Q: Why not store 1,000 points of view when one or two will do?
A: It turns out that there are some good reasons why not! This post will concentrate on two:
1: Where the initial assumptions come from creates a significant human bias.
2: Reducing the number of records dramatically increases error margins.
Human Bias in the underlying Knowledge Graph data
The knowledge graph creates its ontology largely on structured data sources called RDFs (this stands for Resource Description Framework). There are many examples of these on the Internet, such as the IMDB.com but by far the most well-known is Wikipedia… and derived from this: DBpedia. Because Wikipedia is built with such a consistent structure (citation: Balog, “Entity Search” section 2.2.1 p29) it has been able to scale turning a human-based online encyclopaedia into a semi-structured machine-readable information source more than any other RDF on the planet. On top of this, the internal linking within Wikipedia helps to build and clarify the knowledge graph that it is helping Google (and other players, including Inlinks) to build.
Herein lies the problem. Whilst, in theory, anyone is allowed to edit Wikipedia content, few do, compared to the number of people writing content on the Internet as a whole. Even then, Wikipedia has very powerful tools built-in, which makes it very hard for an expert in any given field to affect the Wikipedia content. The content will be reviewed higher and higher up the chain, which means the ultimate control lies in the hands of surprisingly few people. There is an adage in humanity’s quest for power… you hold power if you hold all the cards… (Citation: law 31 from the 48 rules of power). If Google’s knowledge base and AI systems start with taking Wikipedia as a highly trusted source, then they must by definition accept that their trusted source is unduly influenced by human bias.
People that edit Wikipedia pages are NOT normal. They are certainly not representative of society. The majority are not paid to be unbiased, so these users must ultimately have an ulterior motive for editing content. Those that are being paid to be unbiased are therefore experts in ontologies and encyclopaedias… so cannot be experts in the content being curated. They, therefore, rely on the citations from third-party sources instead of critical thought to edit the content. Either way, the bias is obvious and obviously human.
Why more records reduce the chance for bias
The PageRank model is a very effective way of scoring billions, even trillions of pages based on links acting as votes. Until SEOs started to manipulate the system, it was believed (By Page and Brin) to be un-spammable. Obviously, they were wrong … but spammers aside, PageRank was able to take a more balanced view of Human Bias because the initial data set was EVERY page on the Internet (or at least, every page which had a link to it).
Ironically, we can use the PageRank algorithm to demonstrate the human bias within Wikipedia. This was effectively shown when French PhD paper looked at running PageRank over Wikipedia pages alone and found that the page for Carl Linnaeus scored higher than the articles for Jesus or Hitler. However, when PageRank proxies (Majestic and Moz), who both start with every page, not JUST Wikipedia articles looked at these Wikipedia articles, they both came back with more believable weightings. (Citation: PageRank Study of Hitler vs Jesus on Majestic) This happened because every link contains Bias… but quantity and diversity reduce that bias. Wikipedia’s internal linking is extremely effective but ultimately does not stem from a diverse set of data controllers.
The Wikipedia admins number in the thousands… the number of web pages is in the trillions with authors most likely now in the billions. There is simply a huge loss of diversity in the Entity based approach to organising information compared to Google’s original approach. They are both forms of Artificial Intelligence. PageRank is the very definition of iterative machine learning… but the effect a few people can (innocently) have on the results is very different.
Human Bias failing in Search Retrieval Systems has history!
This over-reliance on humans at the start of an Information Retrieval system is far from new! Three very epic fails come to mind.
Yahoo Directory
The very first attempt at organizing the Internet was the Yahoo directory. At one time, every website on earth had been manually listed… but that was a long time ago. It did, however, make Yahoo the most valuable Internet company of its time… but it ultimately was destroyed by the PageRank algorithm as this algorithm did not appear to need human collation. It could grow faster than yahoo could. Yahoo tried to scale by introducing a fee for prioritizing listings, but ultimately gave up the project in favour of machine-based crawling.
MSN: Powered by Looksmart
When Yahoo was top of the pile, Microsoft had eyes on the prize. Their brand before Bing was “MSN” which, at the time, used another human-curated directory at the top of its search results, called Looksmart. Funny story… I ranked (in Looksmart) for “SEO” at the time, so I was called into their office and was ultimately paid to help Looksmart rank IN THEIR OWN DIRECTORY for the term “Search Engine”. Looksmart’s ranking system was not hard to game, it was simply a case of using the right words in the directory submission. So I gave them their ideal listing and their own editors rejected their own submission! Well – I thought it was a funny story. Mel Carson worked for them at the time, before moving to Microsoft… he’ll back me up on this story.
If Microsoft had used its Encarta product (an encyclopedia which challenged and ultimately defeated the Encyclopedia Britannica), instead of Looksmart to head up its results, it may have found out how to create structured entities far sooner than Google, but I guess nobody connected the dots in time.
Google Directory: Powered by the Open Directory Project
Even Google has famously made this mistake in the past. If most of you do not remember Looksmart, I wonder how many less remember Google Directory? Google Directory started with an opensource download of the Open Directory Project and I believe it was augmented by other human-curated directories, including Business.com, possibly Yahoo Directory and maybe Yell. The Open Directory Project was in many ways the precursor to Wikipedia… an influential data set, controlled by a handful of unpaid and unaccountable humans.
The Ethical Dilemma
Janowicz et al have put forward the need to find ways to remove bias from knowledge graphs but highlight the ethical problem in doing so. Data cleansing, in itself, can be described as a failure of the system. History has already shown us, though, that a lack of records in the quest to save space and computation costs may be the greater problem. Humanity and words change and adapt through time. The Knowledge Graph is likely to be slow to react and worse, may in fact act as a counterforce to humanity’s development and adoption of new ideas.
References cited in this article:
Pagerank, Trustflow and the Search Universe (Majestic)
https://eos-book.org/ (Section 2.2.1)
Janowicz, K., Yan, B., Regalia, B., Zhu, R. and Mai, G., 2018. Debiasing Knowledge Graphs: Why Female Presidents are not like Female Popes. In International Semantic Web Conference (P&D/Industry/BlueSky).
Law 31 of the 48 Laws of Power (Book, Robert Greene)
6 Comments
Dixon Jones · 21st August 2019 at 12:53 pm
Thanks to Dawn Anderson for sharing this Youtube video: https://www.youtube.com/watch?v=CguWbbQeruM&fbclid=IwAR2LniNI9G-oRFXCU8uIjd-KDwADMs3xAd1UMyioZPDtq3WhLFHOXxqdF7k – at 25 minutes in, we see that 0.04% of the users of Wikipedia create 50% of all posts! That is one biased data set!
Todd · 22nd August 2019 at 5:38 pm
Sweet read. This makes me feel like a lose in referring value (from SEO) and an experiential internet. I’m liking it.
Dixon Jones · 23rd August 2019 at 9:49 am
An “Experimental Internet” is an interesting way to look at it! 🙂
Alan Milner · 15th November 2019 at 8:14 pm
I’ve just joined this site, and I have already read two important articles on subjects that I have been dealing with for years. How can we have intelligent conversations if all of our data sources are corrupted, and the search engines compromised.
Two funny stories about Wikipedia.
One day, I happened to look up the publication date for Robert Heinlein’s novel, “Citizen of the Galaxy.” As I read the article, it seemed strangely familiar to me, because I had written and posted it on the Heinlein Society’s website. My own writing, not attributed, of course, on Wikipedia. I didn’t know whether to laugh or cry.
On another occasion, I was reading the Wikipedia entry on Abraham Lincoln, once again because I needed a date for an event in his life. As I read through the article, I came across the shibboleth that Lincoln was this poor country bumpkin lawyer, which was of course completely untrue. Lincoln was a highly successful litigator who defended the railroads in personal injury suits and tried more cases before the Illinois Supreme Court than any other lawyer before or since. I put that into the entry on Lincoln. Several months later, I went back to that article and discovered that someone had removed my corrections and replaced the original mythology.
But here’s the point: I know that Wikipedia is unreliable but I keep using it anyway. I had completely forgotten about Encarta. I just tried to find Encarta and discovered two entries about the now-dead project, one of them on Wikipedia, and the other on Britannica.
Gail Lynette Kingswell Trueman · 14th January 2020 at 9:59 am
Sounds like Wikipedia is not just biased, but also gameable, and ripe for takeover – Extreme Rebellion anyone?
Dixon Jones · 14th January 2020 at 10:22 am
🙂 Well – for a system that is supposed to be democratic, I think editors have different levels of autonomy, so you might find all your edits removed pretty fast by the Wikipedia equivalent of the Polit Buro!